
1. 基本数据类型
Java有8中基本数据类型:
数字类:
整数型:byte、short、int、long
浮点型:float、double
字符型:char
布尔型:boolean
2. 基本类型和包装类型
包装类型可以为null,而基本类型不可以。
包装类型可以用于POJO中,而基本类型不可以(数据库的查询结果可能是null,如果使用基本类型的话,因为要自动拆箱,就会抛出 NullPointerException的异常)。
包装类可以用于泛型,而基本类型不可以。
基本数据类型的局部变量存储于Java虚拟机栈的局部变量表中,成员变量存储于Java虚拟机的堆中。而包装类型全部存放于堆中。
包装类型的值相同,但不相等,需使用equals()方法判断。
自动拆箱、自动装箱(JavaSE5后):用户可直接对基本类型和包装类型进行相互赋值,而系统通过 valueOf() 与 xxxValue()等方法完成转换。
包装类型的缓存机制:Byte、Short、Integer、Long这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回True or False。如果在范围内,则复用已有对象,超出范围则创建新对象。
3. 面向对象与面向过程
面向过程倾向于将问题拆解为一个个方法步骤,通过方法执行实现功能。
面向对象先抽象出对象,用对象执行方法的方式解决问题。
面向过程一般比较简答直接,面向对象虽然复杂,但是易于维护、拓展和复用。
面向对象的三大特征:封装、继承、多态
封装:把一个对象的状态信息(属性)隐藏在对象的内部,外界不能直接访问,但可以通过提供的方法来操作。
继承:可以在已存在的类的基础上创建新类,子类拥有父类的全部属性和方法,子类可以拥有自己的方法,子类可以通过自己的方式实现父类的方法。
多态:同一个方法在不同对象上表现出不同的行为,通过继承和方法重写实现。父类的引用可以指向子类的对象,并调用子类重写的方法。三个必要条件为:继承、重写、父类引用指向子类对象。
4. 接口和抽象类
接口用来约束类的行为,抽象类强调所属关系和代码复用。
共同点:都不可直接实例化,需要先被实现或继承才能创建对象。都可以包含抽象方法,即无方法体,在子类或实现类中定义。
不同点:
Java不支持多继承,一个类只能继承一个类。但一个类可以实现多个接口,一个接口也可以继承多个其他接口。
接口中的成员变量只能是public static final类型的,不能被修改且必须有初始值。抽象类的成员变量可以有任何修饰符(private, protected, public),可以在子类中被重新定义或赋值。
Java 8 之前,接口中的方法默认是 public abstract ,也就是只能有方法声明。自 Java 8 起,可以在接口中定义 default(默认) 方法和 static (静态)方法。 自 Java 9 起,接口可以包含 private 方法。抽象类可以包含抽象方法和非抽象方法。抽象方法没有方法体,必须在子类中实现。非抽象方法有具体实现,可以直接在抽象类中使用或在子类中重写。
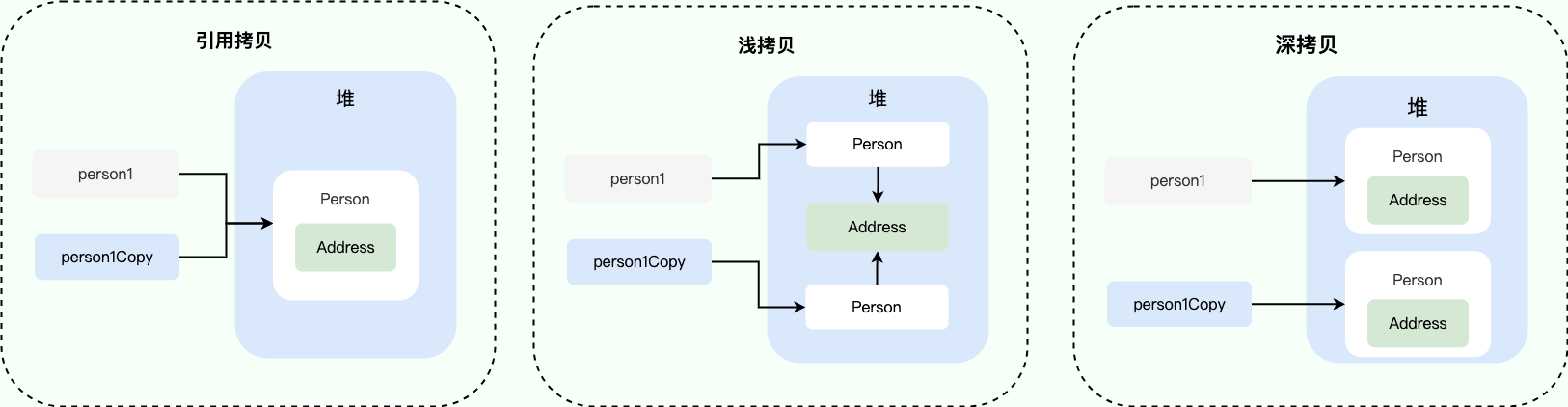
5. 浅拷贝、深拷贝、引用拷贝
这三个概念的核心区别在于:在内存中复制了多少层级的数据,以及新旧对象之间是否还存在关联。
引用拷贝:仅仅复制了对象的内存地址(引用),没有创建任何新对象,两个变量指向堆内存中的同一个对象。这时修改任意一个变量也会影响另一个变量。
浅拷贝:创建一个新对象,然后将原对象中的成员变量复制到新对象中。如果成员是基本类型则拷贝其值。如果成员是引用类型则拷贝其内存地址。新旧对象在内存中是独立的“容器”,但容器里装的“引用类型数据”还是共享的。修改第一层数据(如基本类型),不会影响原对象。但修改内部引用的对象数据,会影响原对象。
深拷贝:创建一个新对象,并递归地将原对象中的所有成员(包括引用的对象、引用对象的引用对象……)全部复制一份。新旧对象在内存中完全独立,互不干涉。
6. ==与equals()
==用于比对两个变量是否指向同一个对象(同一个内存地址)。对于基本数据类型比较的是值,对于引用类型比较的是引用地址是否相同。
equals()方法是Object的方法,比较的也是引用是否相同,但可被子类重写,常见类都进行了重写来比较内容。自定义类要比较内容必须重写equals()方法和hashCode()方法。
==判断需注意:
包装类型缓存机制(前面提到了)、
常量折叠优化(在编译期提前计算出所有由常量组成的表达式,直接把结果写入字节码中,而不是在运行时再计算)、
字符串还需额外注意常量池(字面量字符串会自动放入常量池,字符串常量拼接会触发常量折叠,结果也进入常量池。字符串字面量创建对象时若常量池中已有则会直接赋给当前引用)。
hashCode()是什么?为什么要重写hashCode()方法?
hashCode()是Object的方法,即所有类的方法,该方法可以获取哈希码(确定对象在哈希表中的索引位置),主要为哈希表如HashMap、HashSet等提供高效存取的支持。
Java规定如果两个对象通过equals方法判断为相等,那么他们的hashCode方法必须返回相同的值。但反之不一定(因为可能出现哈希冲突的情况)重写equals方法时必须重写hashCode方法保证相同的对象拥有相同的哈希码从而确保哈希表功能正常。
重写时需注意保证参与equals方法判断的字段都要参与hashCode方法的计算,否则容易出现逻辑矛盾。